哔哩哔哩数据服务中台建设实践 数据处理服务的核心架构与挑战
在数字化浪潮中,数据已成为驱动企业决策与产品创新的核心资产。作为中国领先的年轻人文化社区,哔哩哔哩(B站)拥有海量、多元且高速增长的用户行为与内容数据。为高效赋能业务、提升数据价值,哔哩哔哩积极推进数据服务中台的建设,其中,数据处理服务作为中台的基石,扮演着至关重要的角色。
一、数据处理服务的定位与目标
哔哩哔哩的数据处理服务定位于为全公司提供统一、稳定、高效的数据接入、加工、存储与计算能力。其核心目标在于:
- 统一数据口径:通过标准化的数据处理流程,确保不同业务线使用的数据定义一致,消除“数据孤岛”。
- 提升研发效率:提供易用的数据开发工具与平台,让数据工程师和数据分析师能快速构建数据管道,减少重复开发。
- 保障数据质量与时效:建立完善的数据质量监控体系和实时/准实时处理能力,确保数据的准确性与及时性,支撑实时推荐、风控等关键场景。
- 优化资源成本:通过资源调度优化、计算引擎选型与存储治理,在满足业务需求的有效控制大数据基础设施的成本。
二、核心架构与关键技术栈
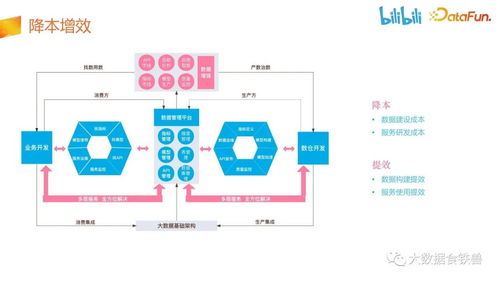
哔哩哔哩的数据处理服务构建在混合云架构之上,其核心分层如下:
- 数据采集与接入层:
- 用户行为日志:通过自研的SDK进行全端(Web、App、PC客户端)埋点采集,数据经消息队列(如Kafka)实时接入。
- 业务数据库:通过CDC(Change Data Capture)技术,实时同步MySQL等OLTP数据库的变更数据。
- 外部数据:建立安全、规范的API或文件交换通道,接入合作伙伴及第三方数据。
- 实时计算层:
- 主要基于 Apache Flink 构建流式计算能力,处理实时推荐、实时监控、实时风控等场景。通过定制化开发与优化,应对B站特有的高并发、低延迟需求,如弹幕、直播互动数据的即时处理。
- 离线计算与存储层:
- 以 Apache Hadoop (HDFS/YARN) 和 Apache Spark 为核心,处理T+1的批量ETL(抽取、转换、加载)任务,构建数据仓库(DW)和数据主题域。
- 数据湖方面,引入 Apache Hudi 或 Iceberg,以支持增量更新、事务保障和更好的查询性能,服务于机器学习特征工程等场景。
- 数据服务与API层:
- 将加工后的数据资产(如用户画像、视频标签、业务指标)通过统一的 数据服务总线 暴露为API。这层实现了数据逻辑与应用的解耦,业务方无需关心底层存储细节,即可高效、安全地获取所需数据。
- 任务调度与运维监控平台:
- 自研或集成开源(如Apache DolphinScheduler)的任务调度系统,实现复杂数据处理DAG(有向无环图)的依赖管理与自动化执行。
- 建立全方位的监控体系,涵盖数据延迟、任务成功率、数据质量(如波动、空值率)以及集群资源水位,实现问题的快速发现与定位。
三、实践中的挑战与应对策略
在建设过程中,哔哩哔哩面临并成功应对了多项挑战:
- 规模与性能挑战:随着用户量与内容量的激增,数据处理规模呈指数级增长。应对策略包括:对计算引擎进行深度调优(如Spark Shuffle优化、Flink状态后端优化);实施分层存储(热、温、冷数据),并采用压缩与编码技术降低成本;引入向量化查询引擎(如Presto/Trino)加速即席查询。
- 数据质量治理挑战:数据源头多、链路长,质量保障困难。B站建立了从数据标准定义、血缘追踪、质量规则配置(如唯一性、有效性校验)到自动告警与工单处理的闭环治理流程,将数据质量管控嵌入到开发流程中。
- 成本控制挑战:大数据资源消耗巨大。通过实施计算任务画像分析、自动识别并优化“长尾”低效任务;推动存储生命周期管理,定期清理无效数据;采用弹性扩缩容策略,根据业务波峰波谷动态调整资源,实现精细化成本运营。
- 安全与合规挑战:严格遵循《数据安全法》《个人信息保护法》等法规。数据处理服务内置了数据分级分类、脱敏加密、访问权限控制(基于RBAC模型)和操作审计功能,确保数据在流动与使用过程中的安全合规。
四、价值与未来展望
通过建设强大的数据处理服务中台,哔哩哔哩实现了数据资产的沉淀与高效复用,显著提升了从数据产生到业务洞察的端到端效率。它不仅支撑了首页推荐、搜索排序、广告投放等核心业务的智能化升级,也为社区运营、内容创作激励等提供了精准的数据洞察。
哔哩哔哩的数据处理服务将继续向 智能化(如基于AI的任务自动优化与故障预测)、 实时化(更广泛的实时数据服务覆盖)和 平台化/自助化(降低使用门槛,让更多业务人员能自主进行数据探索与分析)的方向演进,持续夯实公司的数据驱动能力,为构建更富活力的“Z世代”文化社区保驾护航。
如若转载,请注明出处:http://www.dmbcd.com/product/9.html
更新时间:2026-06-19 22:07:17